머신러닝 3: 혼공머신 4장
4장: 다양한 분류 알고리즘
로지스틱 회귀
로제스틱 회귀란??
- 선형 회귀와 동일하게 선형 방정식을 학습하지만 선형 회귀와 달리 로지스틱 회귀는 분류 모델이다.
- $z = ax_1 + bx_2 + c$
- z는 어떤 값도 가능하지만 확률이 되려면 시그모이드 함수(또는 로지스틱 함수)를 이용하여 0~1 사이 값이 되어야 한다.
시그모이드 함수: $\sigma = \frac{1}{1+e^{-z}}$
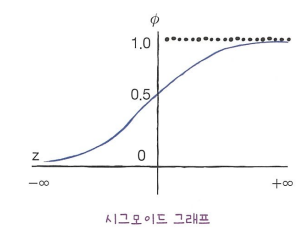
선형 방정식의 출력 z의 음수를 사용하여 자연 상수 e를 거듭제곱하고 1을 더한 값의 역수를 취해야 위 시그모이드 그래프를 그릴 수 있다.
- z가 무한하게 큰 음수일 경우 이 함수는 0에 가까워지고 z가 무한하데 큰 양수일 경우 1에 가까워진다.
- z는 어떤 값도 가능하지만 확률이 되려면 시그모이드 함수(또는 로지스틱 함수)를 이용하여 0~1 사이 값이 되어야 한다.
- $z = ax_1 + bx_2 + c$
1
2
3
4
5
6
7
8
import numpy as np
import matplotlib.pyplot as plt
z = np.arange(-5, 5, 0.1)
sigma = 1 / (1+ np.exp(-z))
plt.plot(z, sigma)
plt.show()
- 파이선에서 사이킷런의 LogisticRegression 클래스를 이용하여 로지스틱 회귀 모델을 만들어 학습할 수 있다.
로지스틱 회귀로 이진 분류 수행하기
불리언 인덱싱을 이용하여 넘파이 배열은 True, False 값을 전달하여 행을 선택할 수 있다.
1
2
char_arr = np.array(['A', 'B', 'C', 'D', 'E'])
print(char_arr[[True, False, True, False, False]]) # ['A' 'C']을 출력
비교 연산자를 이용하면 고르고 싶은 행을 모두 True로 만들 수 있다. 또한 OR 연산자를 이용하면 여러 행을 선택할 수 있다.
1
2
3
bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt')
train_bream_smelt = train_scaled[bream_smelt_indexes]
target_bream_smelt = train_target[bream_smelt_indexes]
위 예시에서 bream_smelt_indexes 배열은 도미와 빙어일 경우 True이고 그 외는 모두 False 값이 들어가고 이 배열을 사용하여 train_scaled와 train_target 배열에 불리언 인덱싱을 적용하여 도미와 빙어 데이터만 들어간다.
사이킷런은 linear_model 패키지 아래에 LogisticRegression 클래스를 이용하여 로지스틱 모델을 만들 수 있다.
1
2
3
4
5
6
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt, target_bream_smelt)
print(lr.predict(train_bream_smelt[:5])) # train_bream_smelt에 있는 처음 5개 샘플을 예측해본다.
KNeighborsClassifier와 마찬가리로 예측 확률은 predict_proba() 메서드를 이용하여 train_bream_smelt에 있는 처음 5개 샘플의 예측 확률을 출력한다. 그리고 classes_ 속성을 이용하면 Bream과 Smelt 중에 어떤 것이 음성 클래스인지 어떤 것이 양성 클래스인지 확인할 수 있다.
1
2
lr.predict_proba(train_bream_smelt[:5])
lr.classes_ # 타깃값을 알파벳순으로 정령되는 것을 볼 수 있다
또한 LogisticRegression 클래스에 있는 decision_function() 메서드를 이용하면 z 값을 출력할 수 있다.
1
2
3
4
5
decisions = lr.decision_function(train_bream_smelt[:5])
print(decisions) # 출력된 값을 시그모이드 함수에 통과시켜보면 확률을 얻는다
from scipy.special import expit # 사이킷런에 있는 시그모이드 함수
print(expit(decisions)) # predict_proba() 출력된 값과 동일한다
로지스틱 회귀로 다중 분류 수행하기
- 여러 개의 클래스를 분류
LogisticRegression 클래스는 기본적으로 반복적인 알고리즘으로 max_iter 매개변수에서 반복 횟수를 지정하며 기본값은 100이다.
- 기본값으로 지정하는데 수렴하지 않은 경우(즉 반복 횟수가 부족하다는 경고가 발생하는 경우) max_iter 값을 늘려야 된다.
LogisticRegression은 기본적으로 릿지 회귀와 같이 계수의 제곱을 규제(즉 L2 규제)한다.
- 릿지 회귀와 반대로 LogisticRegression에 있는 C 매개변수는 작을수록 규제가 커진다.
- 기본값: 1
이진 분류와 달리 다중분류는 소프트맥스 함수를 사용하여 여러 개의 z 값을 확률로 변환한다.
- 소프트맥스 함수는 정규화된 지수 함수라고도 부름
- 계산 방법:
- $e_{sum} = e^{z_1} + e^{z_2} + … + e^{z_n}$
- $s_1 = \frac{e^{z_1}}{e_{sum}}, s_2 = \frac{e^{z_2}}{e_{sum}}, … , s_n = \frac{e^{z_n}}{e_{sum}}$
확률적 경사 하강법
적진적인 학습
- 앞서 훈련한 모델을 버리지 않고 새로운 데이터에 대해서만 조금씩 더 훈련하는 학습
- 대표적인 알고리즘은 확률적 경사 하강법 (Stochastic Gradient Descent)
확률적 경사 하강법
- 확룰적이란: ‘무작위하게’ 혹은 ‘랜덤하게’의 기술적인 표현
- 경사란: 기울기
- 하강법이란: 내려가는 방법
- SGD의 목표: 가장 가파른 경사를 따라 원하는 지점에 도달하는 것
- 가장 가파른 길을 찾아 내려오지만 조금씩 내려오는 것이 중요한다 –> 모델을 훈련
- 전체 샘플을 사용하지 않고 딱 하나의 샘플을 훈련 세트에서 랜덤하게 골라 가장 가파른 길을 찾는다.
- 모든 샘플을 다 사용했지만 산을 다 내려오지 못한 경우: 다시 처음부터 시작
- 에포크란: 훈련 세트를 한 번 모두 사용하는 과정
- 일반적으로 SGD는 수십, 수백 번 이상 에포크를 수행
- 에포크란: 훈련 세트를 한 번 모두 사용하는 과정
미니배치 경사 하강법
- 무작위로 여러 개의 샘플을 사용하여 경사 하강법 수행하는 방식
배치 경사 하강법
- 한 번 경사로를 따라 이동하기 위하여 전체 샘플을 사용하는 방식
- 가장 안전적인 방법이지만 전체 데이터를 사용하면 그만큼 컴퓨터 자원을 많이 사용하게 된다

손실 함수 (Loss Function)
- 어떤 문제에서 머신러닝 알고리즘이 얼마나 엉터리인지를 측정하는 기준
- 손실 함수의 값이 작을수록 좋다.
| 손실 함수 | 비용함수 |
|---|---|
| 샘플 하나에 대한 손실을 정의 | 훈련 세트에 있는 모든 샘플에 대한 손실 함수의 합 |
산의 경사면은 확실히 연속적이어아 하지만 정확도가 듬섬듬성하게 나올 수도 있어서 손실 함수는 다른 방법으로 계산해야 된다.
로지스틱 손실 함수
- 이진 쿠로스엔트로피 손실 함수(binary cross-entropy function)라고도 부름
- 로그 함수를 적용하여 연속적인 손실 함수를 얻을 수 있는 방식
- 계산 방법:
- 타깃 = 1일 때 $-\log{(예측 확률)}$
- 확률이 1에서 멀어질수록 손실은 아주 큰 양수가 된다
- 타깃 = 0일 때 $-\log{(1-예측 확률)}$
- 확률이 0에서 멀저질수록 손실은 아주 큰 양수가 된다.
- 타깃 = 1일 때 $-\log{(예측 확률)}$
SGDClassifier
모델을 만들기 전에 데이터 전처리 과정을 진행해야 되고 훈련 세트에서 학습한 통계 값으로 테스트 세트도 변환해야 된다.
1
2
3
4
5
6
7
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
사이킷런에서 확률적 경사 하강법을 제공하는 대표적인 분류용 클래스는 SGDClassifier이다.
- SGDClassifier의 객체를 만들 때 2개의 매개변수를 지정한다
- loss: 손실 함수의 종류를 지정
- max_iter: 수행할 에포크 횟수를 지정
1
2
3
4
5
6
7
8
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log', max_iter=10, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
partial_fit() 메서드를 이용하여 다시 만들지 않고 훈련한 모델 sc를 1 에포크씩 이어서 추가로 더 훈련할 수 있다.
1
2
3
sc.partial_fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
에포크와 과대/과소적합
- 에포크 횟수에 따라 과소적합이나 과대적합을 발생할 수 있다.
- 에포크 횟수가 적은 경우: 학습이 부족할 수도 있다
- 에포크 횟수가 너무 많은 경우: 훈련 세트에만 잘 맞게 학습된다.

위 그래프를 보면 훈련 세트 점수는 에포크가 진행될수록 꾸준히 증가하지만 테스트 세트 점수는 어느 순간 감소하기 시작한다 –> 과대적합 발생
- 조기 종료(early stopping)이란: 과대적합이 시작하기 전에 훈련을 멈추는 것
1
2
3
4
5
6
7
8
import numpy as np
sc = SGDClassifier(loss='log', random_state=42)
train_sore = []
test_score = []
classes = np.unique(train_target)
300번의 에포크 동안 훈련을 반복하여 진행하고 반복마다 훈련 세트와 테스트 세트의 점수를 계산하여 train_score, test_score 리스트에 추가한다.
1
2
3
4
for _ in range(0, 300):
sc.partial_fit(train_scaled, train_target, classes=classes)
train_score.append(sc.score(train_scaled, train_target))
test_score.append(sc.score(test_scaled, test_target))
다음, 그래프를 그려보고 테스트 세트의 가장 높은 점수하고 훈련 세트의 점수와 테스트 세트의 점수가 가장 가까웠을 때의 에포크를 찾아 선택하여 최적의 SGD 모델을 만든다.
1
2
3
4
5
sc = SGDClassifier(loss='log', max_iter=100, tol=None, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
SGDClassifier는 일정 에포크 동안 성능이 향상되지 않으면 더 훈련하지 않고 자동으로 멈춘다. tol 매개변수에서 향상될 최솟값을 지정할 수 있다. 위의 코드에서는 tol 매개변수를 None으로 지정하여 자동으로 멈추지 않고 max_iter=100 만큼 무조건 반복하도록 하였다.
또한 SGDClassifier의 loss 매개변수를 기본적인 값은 ‘hinge’이다.
- 힌지 손실은 서포트 벡터 머신(SVM)이라는 또 다른 머신러닝 알고리즘을 위한 손실 함수이다.