머신러닝 1: 혼공머신 1장~2장
1장: 나의 첫 머신러닝
인공지능이란?
- 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술이다.
인공지능의 역사: 태둥기와 황금기
인공지능 태둥기
- 1943년: 워런 매컬러와 원터 피츠는 최초로 뇌의 뉴런 개념 발표했다
- 1950년: 앨런 튜링이 인공지능이 사람과 같은 지능을 가졌는지 테스트할 수 있는 튜링 테스트를 발표했다
- 1956년: 다트머스 AI 컨퍼런스 진행했다
인공지능 황금기
- 1957년: 프랑크 로젠블라트가 퍼셉트론을 발표했습니다
- 1959년: 데이비드 허블과 토르스텐 비셀이 시각 피질에 있는 뉴런 기능을 연구했다
인공일반지능 vs. 약인공지능
| 인공일반지능 | 약인공지능 |
|---|---|
| 사람과 구분하기 어렵다는 지능 | 사람의 일을 도와줄 수 있는 만큼만 가능 |
| 아직까지 도달하지 않는다 | 현실에 있는 인공지능 |
머신러닝이란?
- 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
- 인공지능의 하위 분야 중에 핵심 분야이다
- 대표적인 라이브러리: scikit-learn
딥러닝이란?
- 인공 신경망이라는 머신러닝 알고리즘을 통칭한다
- 대표적인 라이브러리: TensorFlow, PyTorch
분류
머신러닝에서 여러 개의 종류(혹은 클래스) 중 하나를 구별해 내는 문제 이진 분류: 2개의 클래스 중 하는를 고르는 문제
생선 분류기 예시
- 문제: 어떤 생선은 도미인지 아닌지 판단
- 간단한 알고리즘:
1 2
if fish_length >= 30: print("도미")
- 하지만 도미의 크기는 무조건 30cm 이상이라고 말할 수 없고 어떤 생선의 크기는 30cm 이상이면 무조건 도미라고 말할 수 없어 위 코드에서 문제점 생긴다
- 해결: 머신러닝
- 하지만 도미의 크기는 무조건 30cm 이상이라고 말할 수 없고 어떤 생선의 크기는 30cm 이상이면 무조건 도미라고 말할 수 없어 위 코드에서 문제점 생긴다
- 머신러닝은 스스로 기준을 찾아서 일(분류)를 한다
- 누구도 어떤 기준을 이용하는지 알려주지 않게 분류
- 기준을 찾는 방법:
- 도미 데이터 보면 어떤 생선이 도미인지를 구분할 기준을 찾는다
첫 번째 머신러닝 프로그램
k-최근접 이옷(k-Nearest Neighbours(k-NN)) 알고리즘을 사용해 도미와 빙어 데이터를 구분해 볼 수 있다.
- k-최근접 이옷이란?
- 어떤 데이터에 대한 답을 구할 때 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 선택하는 알고리즘
scikit-learn의 fit() 메서드는 주어진 데이터로 알고리즘을 훈련시킨 뒤 훈련한다.
1
kn.fit(fish_data, fish_target)
훈련한 후 score() 메서드를 이용하여 모델 kn이 얼마나 잘 훈련되었는지 평가할 수 있다.
- 0에서 1 사이의 값을 반환
1
kn.score(fish_data, fish_target)
predict() 메서드는 새로운 데이터의 정답을 예측한다.
- (target class에서 가정한 값에 따라) 0이나 1 반환
- 예를 들어 교재에서 도미는 1, 빙어는 0으로 가정하므로 아래 코드는 1(즉 도미)를 변환한다
1
kn.predict([[30, 600]])
KNeighborsClassifier 클래스의 기본값은 5이므로 아랫모델 가까운 5개의 데이터를 이용하여 학습했는데 이 기준은 n_neighbors 매개변수로 바꿀 수 있다.
1
kn49 = KNeighborsClassifier(n_neighbors=49) # 35 + 14 = 49이므로 49로 바꿔 봤다.
아랫코드처럼 가까운 49개의 데이터를 이용하므로 kn49의 score는 35/49 (도미의 수/최종 생선의 수)와 같다.
2장 데이터 다루기
지도학습 vs. 비지도학습
| 지도학습 | 비지도학습 |
|---|---|
| 훈련하기 위한 데이터와 정답 필요 | 훈련하기 위한 정답 불필요 |
지도학습
- 데이터와 정답을 입력과 타깃이라 한다
- 둘을 합쳐 훈련 데이터라고 부름
- 입력에 각 클래스는 특성이라 한다

- 정답(타깃)이 있으니 알고리즘이 정답을 맞히는 것을 학습한다
훈련 세트와 테스트 세트
- 훈련 후 훈련에 사용되는 데이터와 다른 데이터를 이용해야 모델을 제대로 평가할 수 있다.
- 훈련에 사용되는 데이터를 훈련 세트라고 하고 평가에 사용되는 데이터를 테스트 세트라고 한다
샘플링 편향
- 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않으면 샘플링이 한쪽으로 치우쳤다는 의미
numpy
- 파이썬의 대표적인 배열 라이브러리
- 2차원 리스트를 표현할 수 있다
- 2차원 리스트를 표현할 수 있다
- 파이썬 리스트를 넘파이 배열로 바꾸기 위하여 넘파이 array() 함수를 사용한다.
1 2
input_arr = np.array(fish_data) target_arr = np.array(fish_target)
- shape 속성을 이용하여 배열의 크기를 확인할 수 있다
1
print(input_arr.shape) # (샘플 수, 특징 수)로 형식으로 출력
- 넘파이 arange() 함수는 0에서부터 샘플 수 - 1까지 1씩 증가하는 인덱스를 간단히 만들 수 있는 함수이다
- 다음은 random 패키지 아래에 있는 shuffle() 함수는 주어진 배열을 무작위로 섞는다.
1 2 3
np.random.seed(42) # 일정한 결과를 얻을 수 있기 위하여 초기에 랜덤 시드를 지정한다 index = np.arange(49) np.random.shuffle(index)
- 배열 인덱싱: 몇 개의 인덱스로 원소를 나타날 수 있는 넘파이의 기능
- 예를 들어 2번째 샘플과 4번째 샘플을 나타나고 싶으면
1
print(input_arr[[1,3]])
- 예를 들어 2번째 샘플과 4번째 샘플을 나타나고 싶으면
데이터 전처리
넘파이로 데이터 준비하기
- column_stack() 함수는 전달받은 리스트를 일렬로 세운 다음 차례대로 나란히 연결한다
1
np.column_stack(([1,2,3], [4,5,6])) # array([[1, 4], [2, 5], [3, 6]])
- ones()과 zeros() 함수를 이용하여 각 샘플의 타깃 값을 가정할 수 있고 concatenate() 함수를 이용하여 1 배열에서 타깃 값을 합쳐 타깃 데이터를 만들 수 있다.
1
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
사이킷런으로 훈련 세트와 테스트 세트 나누기
- train_test_split() 함수를 이용하여 데이터를 훈련 세트와 테스트 세트로 나눌 수 있다.
1
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, random_state=42) # random_state는 랜덤 시드를 지정하는 매개변수이다
- stratify 매개변수에 타깃 데이터를 전달하면 클래스 비웅에 맞게 데이터를 나눈다
1
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target, stratify=fish_target, random_state=42)
예시: 수상한 도미 한 마리
모델을 학습한 후 새로운 데이터를 주어졌고 예측한 결과는 예상과 다르다. 그러면 맷플롯립을 이용하여 산점도 그래프를 그려 그 언급한 데이터의 5-최근접 이옷은 어느 점인지 확인할 수 있다.
1
2
3
4
5
6
7
8
distances, indexes = kn.neighbors([[25,150]])
plt.scatter(train_input[:0], train_input[:1])
plt.scatter(25, 150, marker='^')
plt.scatter(train_input[indexes,0], train_input[indexes,1], marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
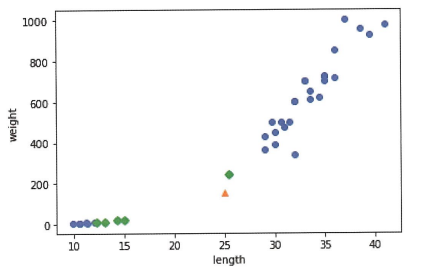
윗그림 보면 초록 다이몬드로 표현되는 가장 가까운 5개의 샘플 중에 도미가 하나 밖에 없는 것을 확인할 수 있다.
기준을 맞춰라
맷플롯립에서 x축 번위를 지정하려면 xlim() 함수를 사용한다 (마찬가지로 y축 범위를 지정하려면 ylim() 함수를 사용한다).
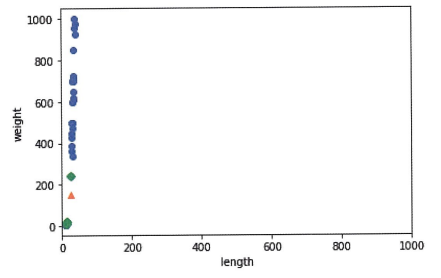
데이터를 표현하는 기준이 다르면 알고리즘이 올바르게 예측할 수 없으므로 특징을 일정한 기준으로 맞춰 주어야 한다. 이런 과정을 데이터 전처리라고 한다.
데이터 전처리
- 가장 널리 사용하는 방법 중 하나는 표준점수(혹은 z 점수)이다.
- 0에서 표준편차의 몇 배만큼 떨어져 있는지 나타낸다
- 계산 방법:
1 2 3 4
mean = np.mean(train_input, axis=0) std = np.std(train_input, axis=0) train_scaled = (train_input - mean)/std # 브로드캐스팅
- 전처리된 데이터를 이용하여 수상한 도미 한 마리 예시를 다시 해결해 보면 모델은 올바르게 도미를 예측한다.
참고: 혼자 공부하는 머신러닝 + 딥러닝